Many institutions within the ecological community have been working together in order to create a common syntax for sharing ecological data and metadata. The effort has produced the Ecological Metadata Language (EML) , which is a formalized specification for expressing information about ecological resources. The language that EML itself is expressed in is the Extensible Markup Language (XML), which is an open, internet-based standard that was designed to enable the creation of discipline specific languages such as EML.
One of the many advantages of using XML is that it allows for a separation of the presentation of a particular resource from its structure. For instance, a research station may want to store metadata in XML text documents, or in an XML database, and present the contents of the XML as HTML (HyperText Markup Language) on a website, or perhaps as published 'data reports' as PDFs (Portable Document Format). An open standard used to enable this sort of functionality is the Extensible Stylesheet Language (XSL), particularly it's XSL Transformation Language component (XSLT).
XML documents consist of a hierarchy of elements (tags/fields), their attributes (properties), and the text content within the elements. The elements, attributes, and content are all referred to as 'nodes' of an XML tree. A simple example would be:
<?xml version="1.0"?>
<dataset>
<identifier system="knb">
altstatt.2.1
</identifier>
<title>Abalone abundance within the California Bight</title>
<originator>
<individualName>
<givenName>Jessica</givenName>
<surName>Altstatt</surName>
</individualName>
<role>owner</role>
</originator>
</dataset>
|
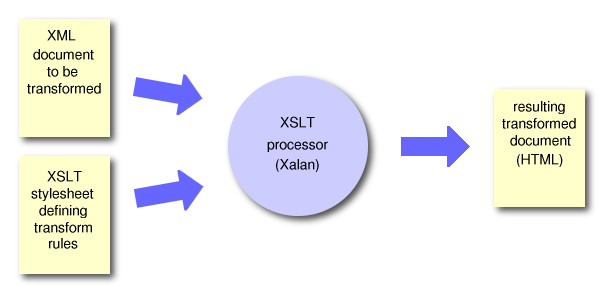
The XML syntax specifically allows for machines to parse the information, but because it is text-based, it is also human readable. However, its presentation could be much more human readable with some formatting. The following schematic diagram shows the components involved in the transformation of an XML document using XSLT.
An XSL Transformation processor is a piece of software that takes both the original XML document and an XSL stylesheet as inputs, and produces the resulting transformed document. In the above case, the output format is HTML. There are a number of XSLT processors on the market today, written in many programming languages. One to note is the Xalan processor, which is a robust, open-source processor from http://xml.apache.org that is implemented in Java.
The XSL stylesheet that is used in the transformation is also expressed as an XML document, but one that describes the transformation rules. Basically, as the processor traverses all of the nodes in the original XML document, it will encounter specific patterns that are described in the stylesheet. Based on the pattern that is found, the processor will perform the transformation that is associated with the matched pattern. The pattern matching is expressed as one or more 'templates' in the stylesheet, which is basically a reusable block of XSLT code that can be applied in multiple places during the parsing of the XML document. An example snippet of code from an XSL stylesheet would be:
<?xml version="1.0"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:output method="html" indent="yes"/>
<xsl:template match="/">
<html>
<head>
<title>Data Catalog</title>
</head>
<body>
<h3>Data set description</h3>
<xsl:apply-templates/>
</body>
</html>
</xsl:template>
<xsl:template match="title">
<xsl:text>Title: </xsl:text><xsl:value-of select="."/><br/>
</xsl:template>
<xsl:template match="identifier">
<xsl:text>Identifier: </xsl:text><xsl:value-of select="."/><br/>
</xsl:template>
<xsl:template match="originator/individualName">
<xsl:text>Originator: </xsl:text>
<xsl:value-of select="./givenName"/>
<xsl:text> </xsl:text>
<xsl:value-of select="./surName"/><br/>
</xsl:template>
<xsl:template match="role">
<xsl:text>Role: </xsl:text><xsl:value-of select="."/><br/>
</xsl:template>
</xsl:stylesheet>
|
The above stylesheet specifies four templates (<template>...</template>) that have associated pattern matches. The first matches the 'root node' of the document, or '/', which is the <dataset> tag, the seconds matches the <title> tag, the third matches the <individualName> tag nested within the <originator> tag, and the fourth matches the <role> tag nested within the <originator> tag. Text values are then taken from these nodes and formatted into the following html within each respective template:
<html>
<head>
<META http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Data Catalog</title>
</head>
<body>
<h3>Data set description</h3>
Identifier:
altstatt.2.1
<br>
Title: Abalone abundance within the California Bight<br>
Originator: Jessica Altstatt<br>
Role: owner<br>
</body>
</html>
|
| Which gets rendered as: |
Data set descriptionIdentifier: altstatt.2.1Title: Abalone abundance within the California Bight Originator: Jessica Altstatt Role: owner |
Today, most implementations of XSLT processors run on server-side systems, such as web servers that need to transform XML into HTML pages for a particular site. An example of such a system is the Metacat database, which is a flexible, open source XML database being developed for the ecological community. Metacat uses XSLT to transform XML for different clients, including web browsers and an XML editing tool written in Java, called Morpho. As web browsers mature in the future, we will see more XML documents being sent straight to the web browser, which will do the transformation locally if they have a reference to the appropriate stylesheet.
This page provides a very short example of XSLT, however, there are many other pages that provide much more in depth, step by step tutorials on using XSLT. The following sites are extremely useful for both understanding XSLT and for using the Xalan processor.
| Java JDK 1.3.1_02 | The Java 2 Platform Software Development Kit version 1.3.1_02. You will need the Java binary directories on your PATH in order to use java and javac. |
| xalan-j_2_3_1-bin.zip | The Xalan XSLT Processor: Xalan 2.3.1 is available at the time of this writing. Both the xalan.jar and xerces.jar files need to be included on your CLASSPATH so that java is able to find the appropriate classes. |
| samples.zip | A zip archive of the above sample XML file, XSL stylesheet, and a Java class called Transform.java, which calls the Xalan processor to tranform XML files on the command line. The archive also includes a stylesheet that will render an entire eml-dataset compliant xml document, validating it against the eml-dataset dtd. |
Contact: Christopher Jones cjones@ecoinformatics.org